AI Education & Case Studies
Search or browse our knowledge base for information on AI, human values at risk, case studies, policy & standards around the globe and AIFCS advocacy.
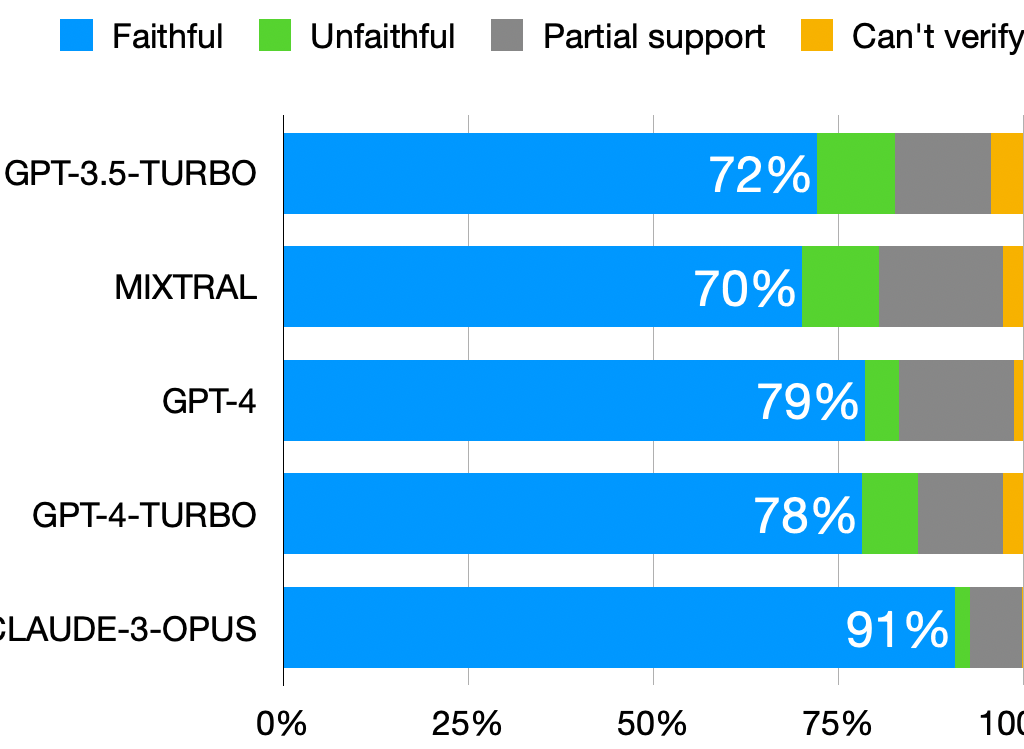
How faithful is text summarisation?




Search or browse our knowledge base for information on AI, human values at risk, case studies, policy & standards around the globe and AIFCS advocacy.